Particle-based SLAM for Autonomous Vehicles
Nishad Gothoskar and Cyrus Tabrizi
##Updated on 5/12 at 11:45 PM. Final report is available here (images/15-418_Final_Report.pdf)
##Updated on 5/11 at 7:24 AM. Added additional preliminary results

Figure 1: Front-facing view of LIDAR data
Summary
We are implementing GPU-accelerated, particle-based Simultaneous Localization and Mapping (SLAM) for use in autonomous vehicles. We’re using techniques from 15-418 and probabilistic robotics to process 3D LIDAR point clouds and IMU data (acceleration and rotation) from the KITTI Vision Benchmark Suite in a way that improves both localization and mapping accuracy.

Figure 2: Picture of the KITTI mapping vehicle
Major Challenges
The main hurdles come from the massive amount of data that each LIDAR collection involves. The KITTI dataset provides complete sensor data at 10Hz and each LIDAR scan returns 100,000+ 3D points in an unsorted list. Even though the work we’re doing on this data is highly parallelizable, most approaches for processing all this data are memory-constrained. The pipeline for SLAM is also very deep and involves a lot of different operations, everything from applying 3D transformations to points to clustering points to sampling normal distributions for each particle in the filter.
Deeply understanding the workload involved in doing SLAM effectively was crucial to our planning and implementation.
For example, realizing that the LIDAR data is both precise and sparse was a reason for us to consider representing the map as a BVH-like tree structure instead of a voxel-based structure. Similarly, realizing that picking the best pose from the particle filter would involve observing the effects of small shifts informed how we decided to compute similarity scores.
Quick summary of our SLAM algorithm
The steps for SLAM are as follows:
- Initialize the particle filter
- Each particle represents a possible pose for the vehicle
- On the first time step, set every particle to (0,0,0,0,0,0)
- Retrieve the LIDAR data
- Each scan contains roughly 100,000+ points
- Retrieve the IMU and gyro data
- Remember! Relying only on IMU and gyro data introduces drift into our map.
- Retrieve the timing data
- The sensor measurements are recorded at roughly 10Hz
- We need to know the exact timing intervals to reduce error
- Offset each particle pose by the measured IMU and timing data
- We want the particles to be an estimate of where the vehicle currently is
- Offset each particle pose by a normal distribution
- We’d use an actual error distribution for the timers, IMU’s etc. if we had one
- Instead, we approximate the error as being gaussian
-
Now we use each particle pose to transform the LIDAR data back into the original reference frame
-
We compare each particle’s transformed LIDAR data to the previous map and compute a similarity score
-
We search the score list and find the particle with the best score. This particle reflects our best estimate of the vehicle’s true pose
-
Using our best estimate of the vehicle pose, we merge the new LIDAR data with our previous map
-
Generate a new particle filter by resampling the old particle filter, using their scores to bias the resampling towards the particles that were most accurate
- Repeat this process
Preliminary Results
The first step was learning the SLAM algorithm enough to first implement it all correctly from scratch. This is a necessary prerequisite to doing it in parallel. Since the problem is mostly the same in 1 dimension as it is in 3 dimensions, we first wrote a particle-based SLAM simulator in Python before moving to 3 dimensions and C++.

Figure 3: Screenshot from SLAM simulation in 1D

Figure 4: Animation from SLAM simulation in 1D
Simultaneously, we needed to figure out how to work with the KITTI dataset. This involves being able to read and manipulate the IMU and LIDAR data. The following shows visualizations of two LIDAR scans which have been realigned into the original reference frame. After this realignment (which includes IMU error), we were able to merge the two point clouds. The following shows that we properly transformed the data in 6 dimensions (translation and rotation in 3D).


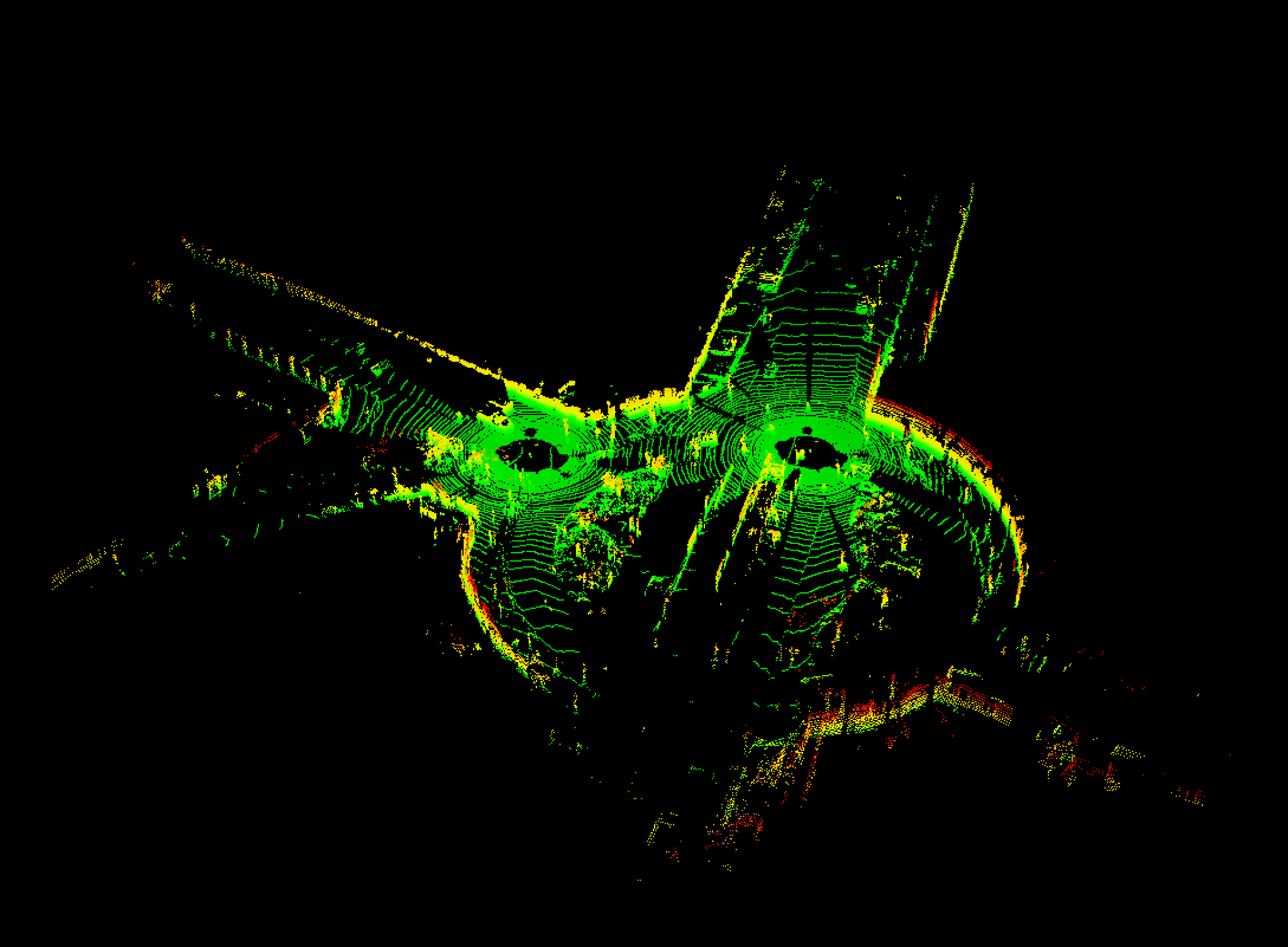
Figure 5: Merging of two lidar scans
The above, however, was done sequentially in Python. After using the starter code to figure out how to read the data logs and manipulate the data correctly, we wrote a CUDA-based parallel implementation that produces the same transformations.
![]()
Figure 6: Python transformation matrix
![]()
Figure 7: CUDA transformation matrix
To parallelize the above, two kernels were written.
In the first kernel, the rotation matrix is obtained. This matrix is composed from three separate roll, pitch and yaw matrices (Rx, Ry and Rz). To generate each of these three matrices, the three input angle values must first be padded with an angle error from a gaussian distribution. Then through some standard matrix math, the composed rotation matrix is made and is saved in the particle’s transform field.
In the second kernel, the full transformation will be generated. First, the velocities are padded with velocity errors from a gaussian distribution. These velocities are then multiplied by a ‘dt’ to get the approximate distance travelled in that step. This delta is then rotated from the vehicle’s new reference frame to the global one using the rotation matrix from the first kernel. Now that the offset delta is known in global coordinates, it is added to the previous known location. This new position is used to add a translation column to the 4x4 homogenous transform matrix, completing the transform.
To achieve the above also required implementing noise lookup tables. Taking inspiration from the circleRenderer assignment, 6 different index tables were installed in addition to a table for a Normal distribution. The index tables hash the thread index into a uniformly shuffled array of indices from 0 to 255. These indices then map the thread to a value sampled from a Normal(0,1) distribution.
Note: The Eigen library was used for Matrix-Matrix and Matrix-Vector operations
Preliminary Timing Results (Averaged over 10 runs)
![]()
Figure 8: Speed analysis for fused transform generation in CUDA
There’s negligible speedup as the blocksize changes. This makes sense since there’s no relationship between particles processed in the same block and the work is uniform across threads (feature no branching or early termination case, except for when indices are out of bounds).
With respect to the speedup observed with the change in workload size, this can largely be attributed to the GPU being underused for smaller workloads. As the workload approaches the maximum number of blocks each SM can execute at once, blocks begins to sit in the queue and the main source of speedup goes away.
What to look forward to on Friday
-
Maps we’ve built from the KITTI dataset
-
Plots of vehicle trajectory with and without SLAM
-
A video showing the construction of the map as the vehicle moves through the scene